Modelagem Multidimensional
Categories:
5 minute read
Cubo de Dados
Um DW tem como principal objetivo servir de repositório para a analise de grandes massas de dados através de consultas OLAP , neste cenário observa-se dados centrais (os fatos ou métricas) que serão consultados sob diversas perspectivas (as dimensões ou parâmetros) criando a abstração do cubo de dados, conforme figura abaixo:
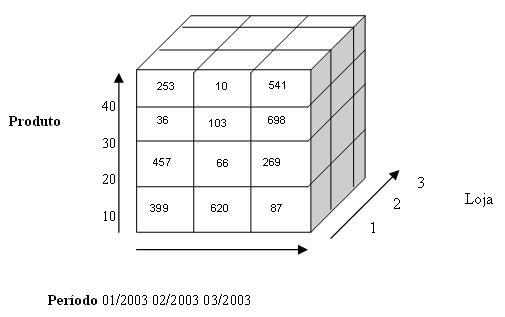
Fonte: http://www.devmedia.com.br/parceiros/fig02.jpg
Conceitualmente uma base de dados multidimensional é representada pelo cubo de dados; mas partindo para o modelo lógico e físico a forma mais simples de representar uma base de dados multidimensional é a figura abaixo:
Modelo Estrela | Floco de Neve
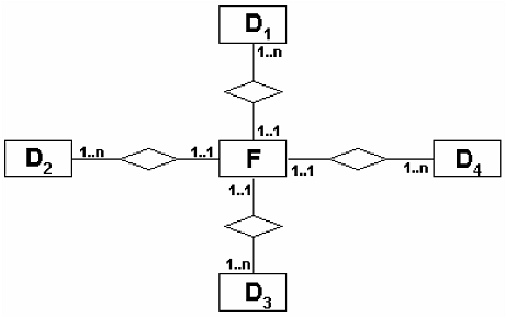
Fonte: http://www.ime.usp.br/~jef/apostila.pdf
Essencialmente teremos no centro do modelo uma ou mais “tabelas fatos” contendo de 0 (zero) à n (várias) métricas cada tabela e nas bordas teremos pelo menos 1 (uma) “tabela dimensão” podendo ter quantas forem necessárias.
Durante o processo de modelagem da base de dados multidimensional, os itens abaixo devem ser analisados cuidadosamente:
- Escopo;
- Granularidade;
- Dimensões e;
- Métricas;
Por último deve-se definir o esquema que será utilizado: Estrela ou Floco de neve.
Escopo
A experiência e o conhecimento do analista de SAD sobre o negócio é fundamental para a correta definição do escopo de um projeto de DW.
É imprescindível ter uma visão do que é importante para o negócio, ou melhor, saber que informação será necessária extrair dos dados armazenados no DW para que a organização obtenha algum conhecimento novo e a partir deste ponto os gestores possam tomar as decisões mais acertadas.
Vale lembrar que cada projeto é único e portanto deve ser analisado individualmente e que muitas variáveis influenciam as decisões, por exemplo: tempo para implantação, custo, capital humano e recursos tecnológicos disponíveis, etc.
Estes dentre outros fatores influenciarão na escolha de um dos dois paradigmas que envolvem os projetos de DW que são as propostas de Inmon e Kimball .
Inmon propõe que o projeto do DW deve partir do DW corporativo para depois desmembrar nos DM departamentais com isto ganha-se na consistência dos dados armazenados mas o tempo para a obtenção de resultados práticos aumenta, em contrapartida Kimball propõe o caminho inverso, partir de DM departamentais para o DW corporativo buscando observar à consistência das informações, neste processo os resultados aparecem mais rapidamente porém o risco de inconsistência aumenta.
O bom senso entre as pessoas envolvidas sempre deve ser levado em conta no momento da decisão do projeto, para se buscar um equilibrio entre o melhor dos dois mundos.
Granularidade
Durante o desenho da solução o analista de SAD define quais métricas serão armazenadas nas tabelas fatos e quais parametros serão armazenados nas tabelas dimensões, observe a figura abaixo.
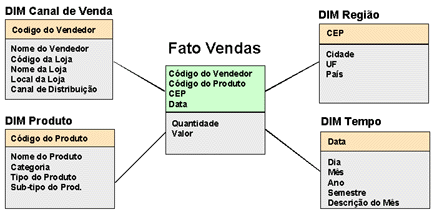
Fonte: http://hub05.neogrid.com.br/Docs/help/pt_BR/release_notes.htm
A definição correta da granularidade de uma tabela fato implica no desempenho das consultas OLAP , tomando como base o modelo proposto imagine os seguintes cenários:
- Poucas lojas e pouca abrangência (poucos CEP´s);
- Muitas lojas e pouca abrangência (poucos CEP´s);
- Poucas lojas e abrangência nacional;
- Muitas lojas e abrangência nacional;
É de se concordar que o volume de dados armazenados na tabela fato na última situação poderá chegar a bilhões de registros, podendo impactar no desempenho das consultas que não necessitem de um detalhamento maior.
Nestes casos uma alternativa é quebrar a tabela fato em domínios menores, onde além de uma tabela com o nível máximo de detalhes existiriam outras tabelas sumarizadas por cidade ou estado por exemplo.
No geral para granularidades distintas teremos tabelas fatos distintas.
Dimensões
Vamos falar um pouco sobre a tabela “dimensão”, um item importante na modelagem multidimensional e que tem algumas caracteristicas próprias que devemos observar:
- Projete a tabela dimensão na perspectivas do usuário. Utilize textos descritivos e códigos que sejam de fácil entendimento do usuário final, não tente economizar alguns bytes neste quesito.
- Evite utilizar técnicas de normalização dos dados. Esta técnica aumenta a complexidade das consultas, impactando no desempenho, além de não compensar a economia de espaço obtida.
- Utilize uma chave primária genérica e simples. Este procedimento evita problemas de atualização que surgem aos utilizar, por exemplo, o próprio código do cliente ou produto como chave primária, além de proporcionar um melhor desempenho na utilização dos índices.
- Utilize múltiplas colunas de atributos. Com isto ficará mais fácil identificar a chave em questão.
Abaixo alguns exemplos de atributos que podem ser utilizados para ajudar a detalhar uma chave facilitando na definição dos parametros da consulta OLAP.
Atributos estruturais para relacionamentos pai-filho;
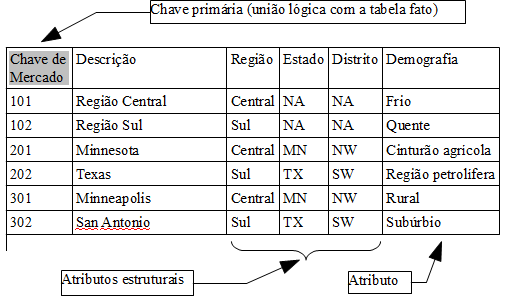
Fonte: HARRISON, Thomas H. Intranet Data Warehouse. São Paulo, Berkeley, 1998. 362 p.
Atributos para definição de nível;
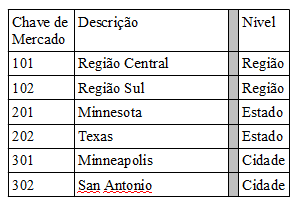
Fonte: HARRISON, Thomas H. Intranet Data Warehouse. São Paulo, Berkeley, 1998. 362 p.
Atributos tipo “flag” de resolução e/ou de seqüência;
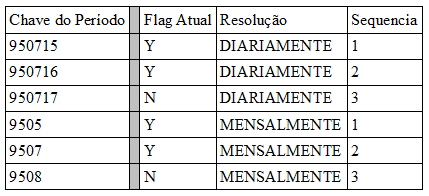
Fonte: HARRISON, Thomas H. Intranet Data Warehouse. São Paulo, Berkeley, 1998. 362 p.
Métricas
Agora vamos aos “fatos”, às “métricas”, ao centro das atenções, pois são as tabelas fatos que irão guardar no data warehouse a respota para todas as questões.
É na tabela fato que o analista de SAD armazenará as métricas do negócio, possibilitando recuperar dados quantitativos e responder por exemplo quanto foi vendido de um determinado produto? em determinada época? em determinado local? dentre outras questões.
Os fatos ou métricas armazenadas podem ser de três tipos:
- Aditivas: São as métricas que podem ser sumarizadas adicionando seus valores ao longo do tempo. Por exemplo o valor, o custo e/ou a quantidade de um pedido podem ser somados independente das combinações dos parametros das dimensões;
- Não-aditivas: É o inverso das aditivas, por exemplo valores percentuais (no geral não são somados) e como normalmente são derivadas de outras métricas aditivas, fica mais prático calcular em tempo de execução do que armazenar estas métricas.
- Semi-aditiva: Estas métricas podem ser sumarizadas apenas em algumas dimensões, como exemplo temos o saldo de uma conta corrente, que pode ser sumarizada na dimensão cliente, na dimensão agência mas não faz sentido somar o saldo da conta ao longo do tempo.
Ampliando esta questão dos tipos de métricas, temos o exemplo da temperatura (métrica não-aditiva) e do saldo da conta (métrica semi-aditiva) que não faz sentido somar, mas podemos utilizar outras operações como média, máximo e mínimo;
Normalmente na tabela fato a chave primária (PK) é composta, sendo que cada elemento é uma chave estrangeira (FK) vinculada à uma tabela dimensão, sendo que a dimensão tempo sempre faz parte deste conjunto.
Em alguns casos podemos ter uma tabela sem fato, onde apenas a relação entre as dimensões já é o suficiente para a área de negócios, conforme o exemplo:
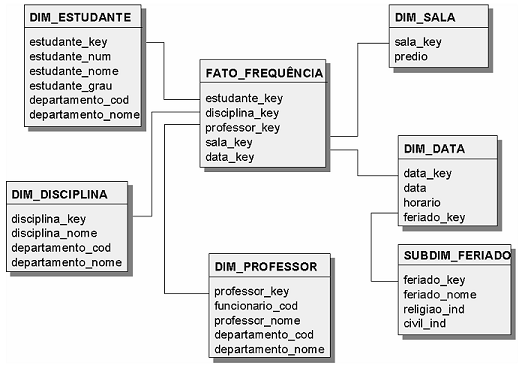
Feedback
Gostou desta página?
Que bom, que gostou! Por favor, tem algo que podemos melhorar?
Que pena! Por favor, me diga o que podemos fazer pra melhorar. Obrigado!